Advanced network testbed users requite specific capabilities from the network interfaces they have. This post outlines how we will provide an avenue for specifying important details that are needed from the network interfaces for an experiment so successfully execute.
Given the following topology, lets say for my pX nodes in the core of the network, I have some specific network requirements.
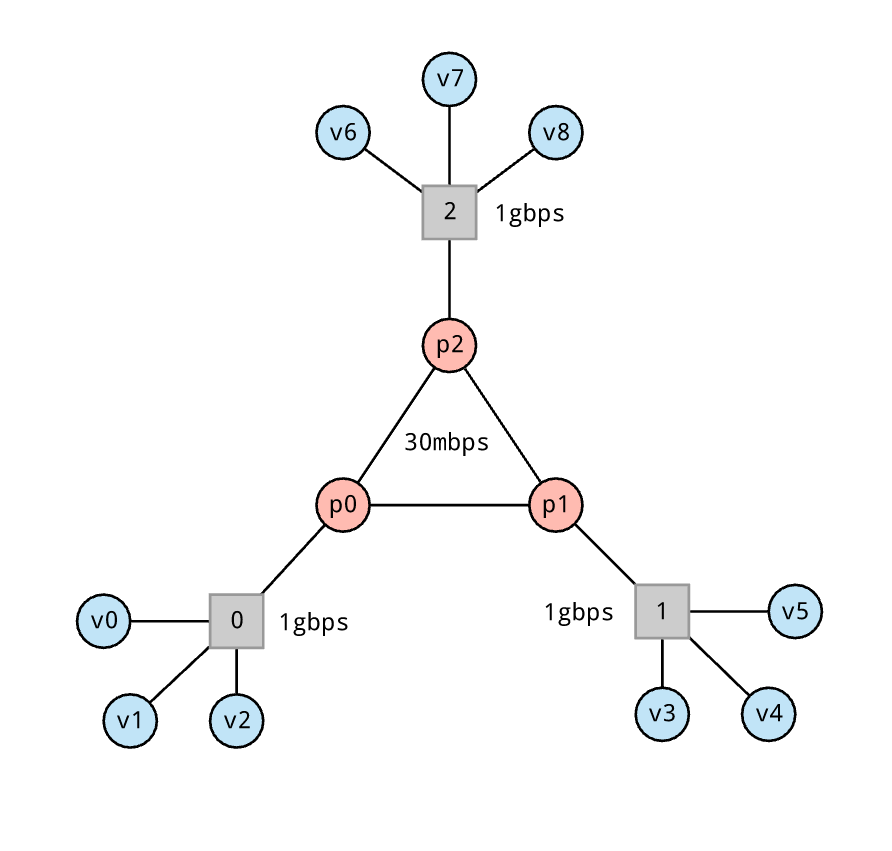
These requirements are
- DPDK capable network interfaces
- At least 8 hardware TX/RX lanes on each interface
A sketch of how this can be specified in an experiment topology is as follows (bottom of file)
from mergexp import *
net = Network('triforce')
def px(name):
return net.node(
name,
memory.capacity >= gb(1),
proc.cores >= 1,
disk.capacity >= gb(100),
metal == True
)
def vx(name):
return net.node(
name,
memory.capacity >= gb(1),
proc.cores >= 4,
disk.capacity >= gb(100),
)
p = [px('p%d'%i) for i in range(3)]
net.connect([p[0], p[1]], link.capacity == mbps(30))
net.connect([p[0], p[2]], link.capacity == mbps(30))
net.connect([p[1], p[2]], link.capacity == mbps(30))
v = [vx('v%d'%i) for i in range(9)]
net.connect([p[0]] + v[0:3], link.capacity == gbps(1))
net.connect([p[1]] + v[3:6], link.capacity == gbps(1))
net.connect([p[2]] + v[6:9], link.capacity == gbps(1))
for machine in p:
for socket in machine.spec.sockets:
socket.require(
link.dpdk == True,
link.queues >= 8,
)
experiment(net)
This is clearly not an exhaustive list of interface properties. More will be added over time, the topic for discussion here is on the general approach of specifying things this way and if there are use cases that may not be covered.