Welcome to 2021 and MergeTB v1. This post goes over what’s new in Merge v1 from an architecture, design and development perspective. To get a sense for what a workflow looks like for an experimenter in v1, take a look at this guided tour through a hello world experiment in v1.
We’ll start with a quick overview of what things are new or changed, and then dive in to how things are plugged into development and operations.
Overview of v1 Changes
-
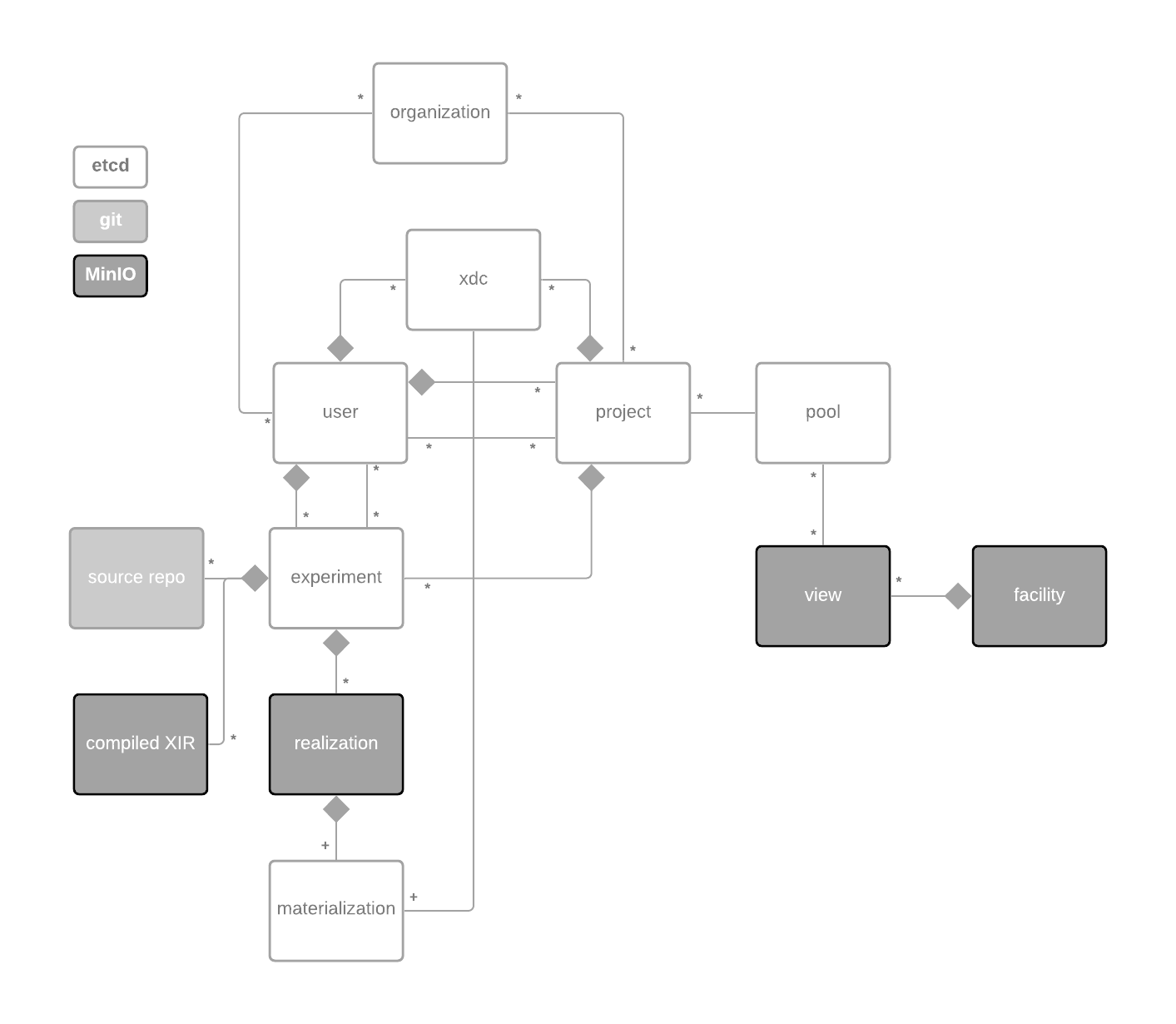
Experiments as Repositories: In Merge v0.9 we approximated a principled versioned workflow with the experiment push pull semantics. In v1, we have Git fully integrated into the portal and define experiments as whole versioned repositories and not just a single file.
-
Leveraging K8s Ingress: In Merge v0.9 we exposed public services as K8s external services and used a standalone HA-proxy/keepalived setup to route traffic into the K8s cluster. In v1 all of this is done by the K8s Ingress mechanism, obviating the need for a standalone external ingress mechanism.
-
Single Integrated Portal API: In v0.9 we had a gRPC API for each core service, an OpenAPI 2.0 spec implementation for experimenter facing capabilities and bunch of code that manually translated data structures and call semantics between the two. In v1 we leverage gRPC-Gateway to act as a single source for data structures and API semantics with a generated OpenAPI 2.0 spec and implementation that automatically bridges between REST and gRPC. This leads to both reduced complexity in the portal itself and clients, and the ability to offer both a REST and gRPC API as public endpoints.
-
Scalable Object Storage: We’ve been talking about this for a long time, now it’s finally here. In v0.9 we stored everything in Etcd. Etcd really does not like storing any values much over 1.5 MiB. When experiments get large and complex, compiled models can easily reach into the 100s of MiB. This has resulted in total lockups of Etcd in production. In v1 we use MinIO for all object types that have the possibility to become large.
-
Reconciler Architecture: In v0.9 you could consider the portal design a centralized orchestration system, where the core services were directly controlled by the API and had no real autonomy of their own. In v1 we’ve adopted the reconciler architecture where the API simply communicates the desired state on behalf of user requests and the core services autonomously observe desired state, current state and continuously drive desired state to curent state. To quote the above link “Because all action is based on observation rather than a state diagram, reconciliation loops are robust to failures and perturbations: when a controller fails or restarts it simply picks up where it left off”. The Cogs already work somewhat in this way in v0.9, in v1 much more so.
-
Protocol Buffers base XIR: In v0.9 XIR was embedded in JSON. This is problematic for 2 primary reasons 1) schema is implicit in code, 2) serialization is space inefficient. The impact of 1 is having no real structure around what defines XIR objects and consistency between subsystems is left up to developers sorting out what data structures should look like by looking at the code that generates them. The impact of 2 is massively inefficient representations for both interchange and storage. Movement to protocol buffers solves both of these problems.
-
Virtualization Support: We now support virtualized nodes, in expression through the Python MX library, interchange through XIR and implementation through Cogs QEMU/KVM integration.
-
Experiment Mass Storage: Experimenters can now define storage volumes either statically, or ephemerally in experiments and attach them to devices. Mass storage is available either as files systems or block devices. This system created by @lincoln is underpinned by Ceph and goes by the development name Rally.
-
Experiment Orchestration: Experience with our first few years of deployemnt with Merge and heaviy use of Ansible as a make-shift experiment orchestrator has shown that while Ansible and the general ecosystem of tools it exists within are great at confirutaion management, they are not orchestration tools. To this end @alefiya has been working on the Orchid Orchestrator as the next evolution of Magi.
-
Certificate Based SSH: SSH keys that are used in a Merge context are now generated by the Merge portal and take a certificate based apporach. This solves several problems that have plagued users, first when jump containers roll, or an XDC name is reused, or a node name is reused SSH will complain about shifting hosts. Second generating and submitting SSH keys, and understanding how SSH works in general has been an obstacle for many users, by having the portal take the initiative to set things up in a way that is guaranteed to work on behalf of users takes away much of this pain for users and operators.
-
Self Contained Authentication: In v0.9 we relied on Auth0 as both an identity provider and an authentication provider. In v1, spearheaded by @glawler we have integrated the Ory identity infrastructure into the Portal. This solves several problems 1) streamlined registration that was a point of confusion for users in v0.9 having to both register with Auth0 and initialize with MergeTB, 2) Support for fully isolated operations, 3) Support of OAuth2 delegation flows to integrate with other services such as GitHub, 4) full control over token issue to create more natural workflows for CLI clients and OAuth2 server based clients.
-
Self Contained Registry: The portal now comes with a built-in registry. We got this by switching from vanilla K8s to OKD. This allows for the images in the portal to operate on a push-in model rather than a pull-from model. This allows the portal to have a self contained installation and also, to act as a container provider for facilities further bolstering capabilities for walled garden environments.
-
Self Contained Installers: Both the portal and facility technology stacks now come with a single, standalone, self-contained installer.
-
Cyber Physical Systems Support: Experimenters can now describe physical objects and a set of differential-algebraic equations, define connections between object variables, define sensors and actuators that connect physical objects to cyber ones and use the simulation API to control a CPS experiment.
-
Organizations: The portal now has the concept of an Organization. If a user or project joins an organization, they are delegating authority to manage their account or project to the maintainers of that organization. Organization maintainers can initialize and freeze users within their organizations. This is initially in support of educational use cases for labs and classrooms, but may also turn out to be useful for large labs or companies or government groups using Merge.