Background
One of the most basic things a network testbed must do is create isolated virtual networks between host machine ports according to an experiment topology. We refer to the experiment network as the upper network and the testbed network as the lower network. Creating virtual networks that overlay the upper network onto the lower network takes place in several stages and levels of abstraction.
To start with a realization is computed. This is a logical embedding of the upper network onto the lower network without regard to the implementation details of actually constructing such an embedding through something like a set of VXLAN segments. The goal here is to simply find an embedding where the properties of the lower network are sufficient to satisfy the constraints of the upper network. The realization phase must also consider what other virtual networks are currently resident on the lower sub-network the upper network will be embedded into to determine if the upper network constraints are satisfiable. To do this, the realization engine must walk the lower-network path of each upper-network link for a given embedding and verify that the constraints of that link are satisfied. This requires an efficient means of network traversal between endpoints.
Up till now, we have taken the approach of pre-computing a solution to the all-pairs shortest-path (APSP) problem, which we refer to as the Dijkstra forest. Using the pre-computed forest, we can efficiently traverse the path between any two interfaces in the testbed without having to do a branch and bound search. This has served us well up to this point, however, as Merge grows to interconnect large testbed facilities we do run into some scaling problems. In particular APSP by definition requires us to compute the full path from every interface to every other interface resulting in an N^2 problem in the number of interfaces (in terms of size, it’s actually worse than that for computation). For DCompTB alone this results in 2.8M+ paths.
When you take a step back and think about what’s actually needed, it’s not APSP, it’s a routing table for the ecosystem of testbeds you are working with. Given some interface a how to get to interface b is a question of routing. In what follows, I propose a prefix-based routing scheme that will allow for efficient lower-network walks that only requires a prefix route for each destination from a given source. Back of the napkin complexity calculation leads me to believe this in an N*M problem where N is the number of host interfaces and M is the number of unique prefixes.
Approach
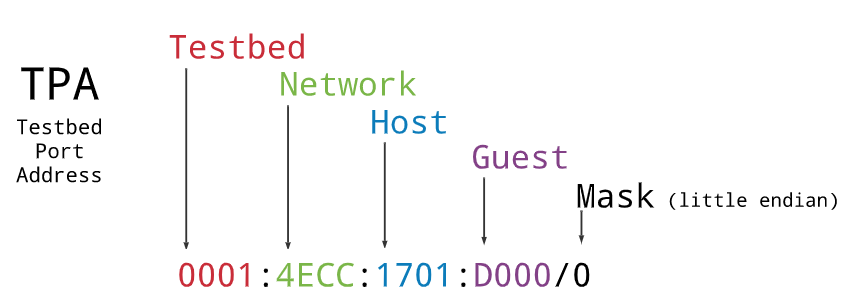
My approach to prefix routing for testbed interfaces starts with an address format.
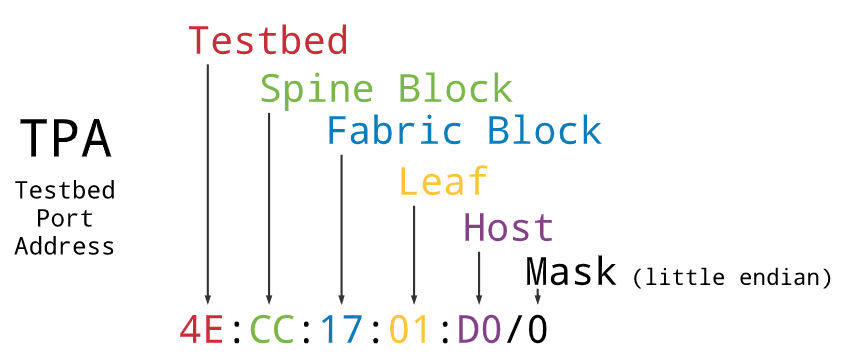
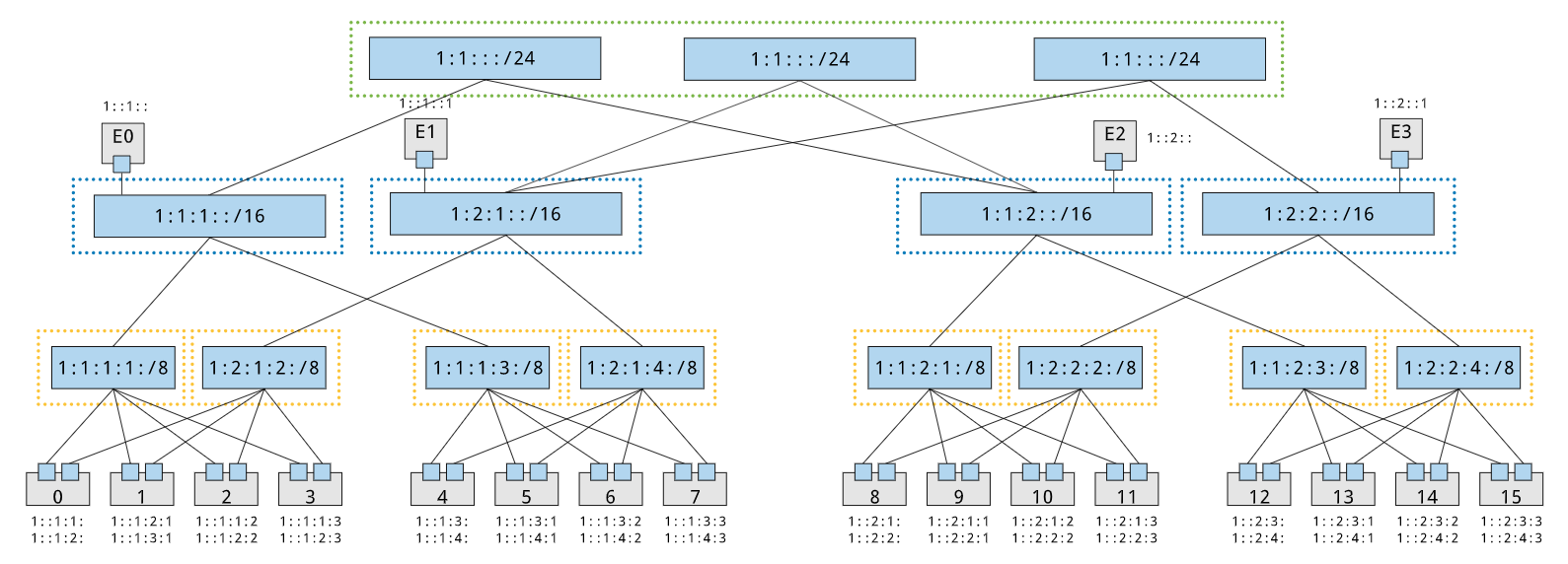
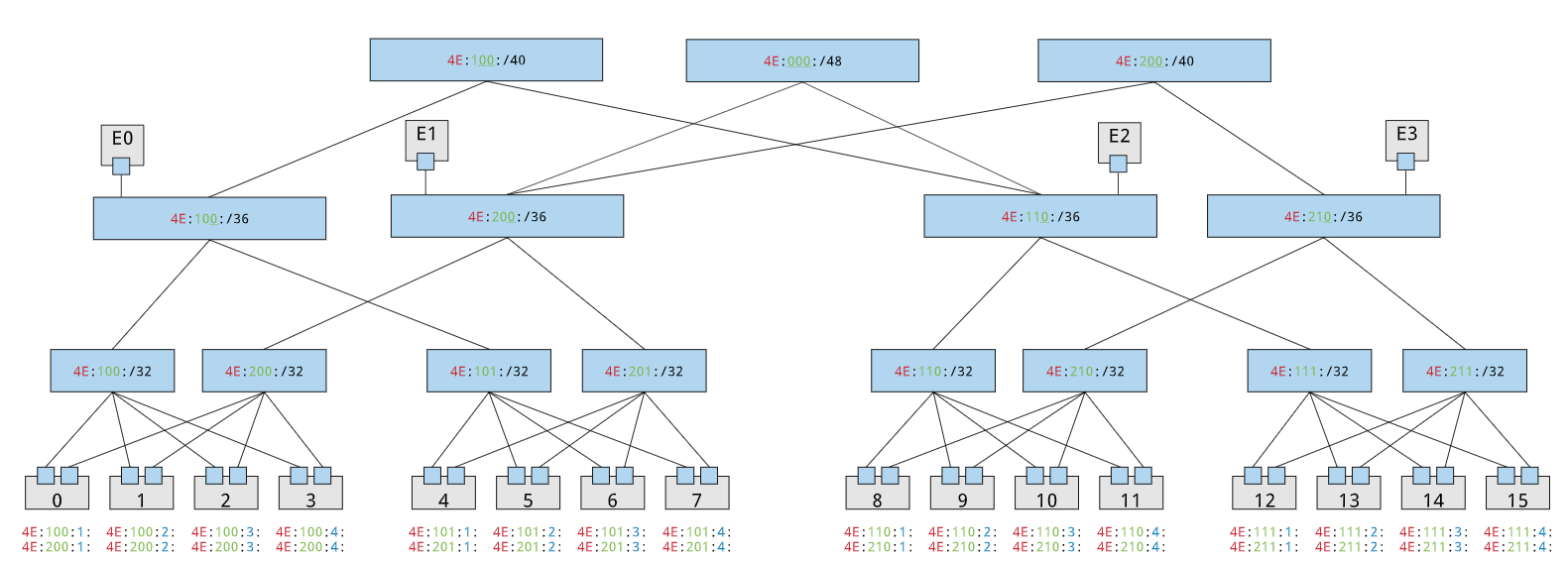
Each physical interface in the testbed is assigned one of these addresses. (One could imagine one more layer for VM/container guests, seems like a good idea, but I need to give it more thought). Given this structure we can create a prefix tree that corresponds to the physical construction of a testbed network.
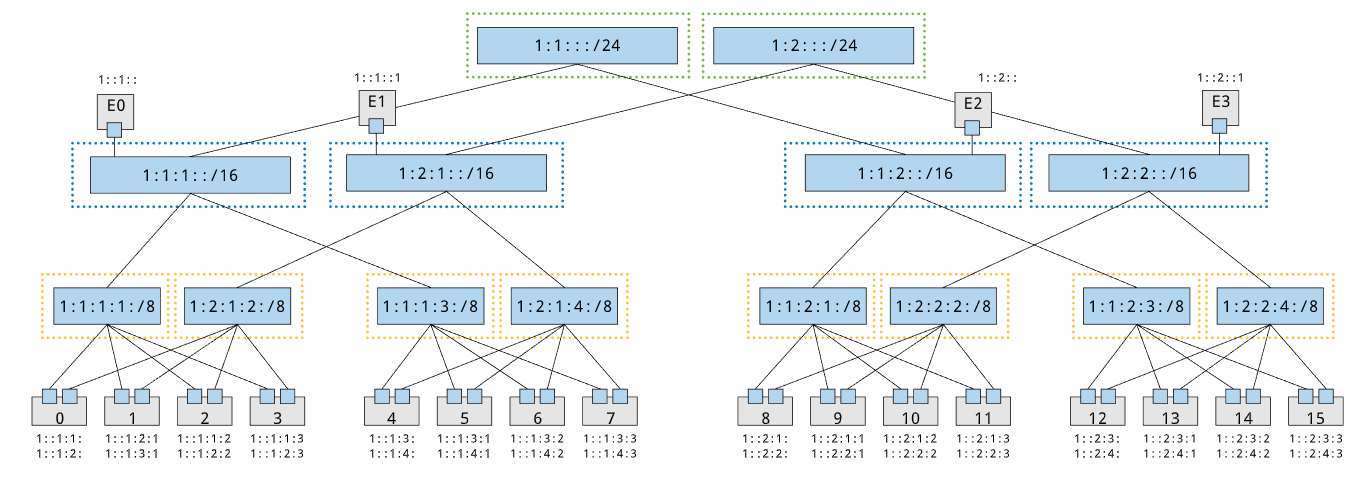
In this case we have a classic hierarchical network, and each spine block and fabric block is a single spine and fabric. However, when folded-Clos networks (often referred to as fattree networks) come into play blocks become less trivial.
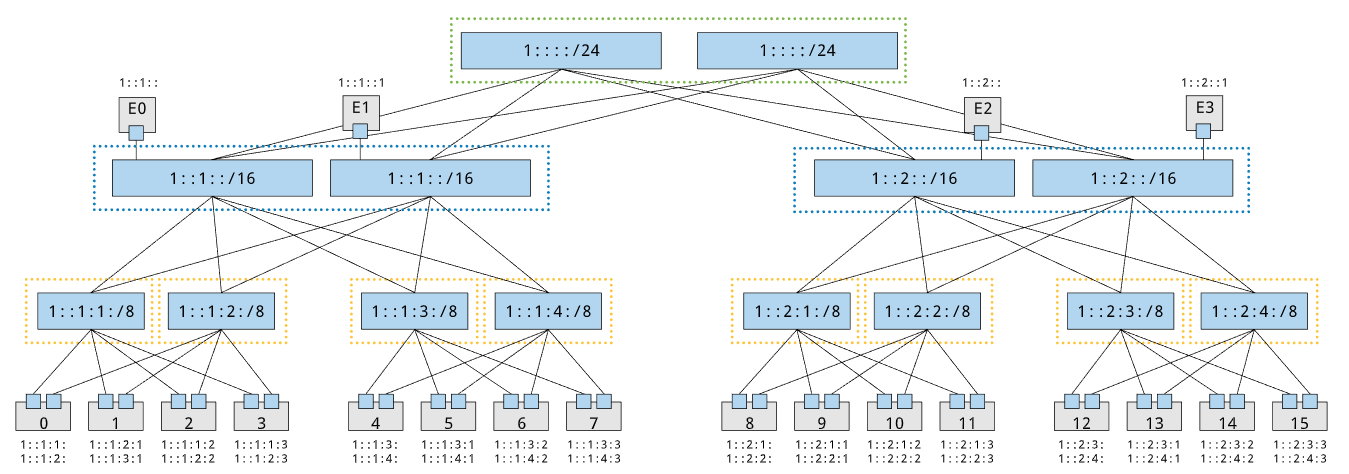
In this situation, because multipath routing conditions exist a given address can be reached from multiple spines or fabrics. So for the addressing format to be consistent, fabrics and spines that have multiple paths to destination hosts must be aggregated into blocks. In this case there is one spine block and two fabric blocks
Testbed Address Assignment
When a new testbed facility is commissioned with a Merge portal, a tesbed address (the leading 8 bits of the TPA) is allocated for the new facility, saved in the portal data store. The testbed facility can then assign addresses within their testbed address block.