MergeTB Reconciler Architecture Overview
The vast majority of services for the reference MergeTB Portal and Facility operate under
the design pattern known as the reconciler controller loop
under a Publisher/Subscriber design pattern.
Reconciler Controller Loop
Under the reconciler controller loop, instead of telling a service what to do,
we tell the service what we want done and let the service figure out what it needs to do
to get it done.
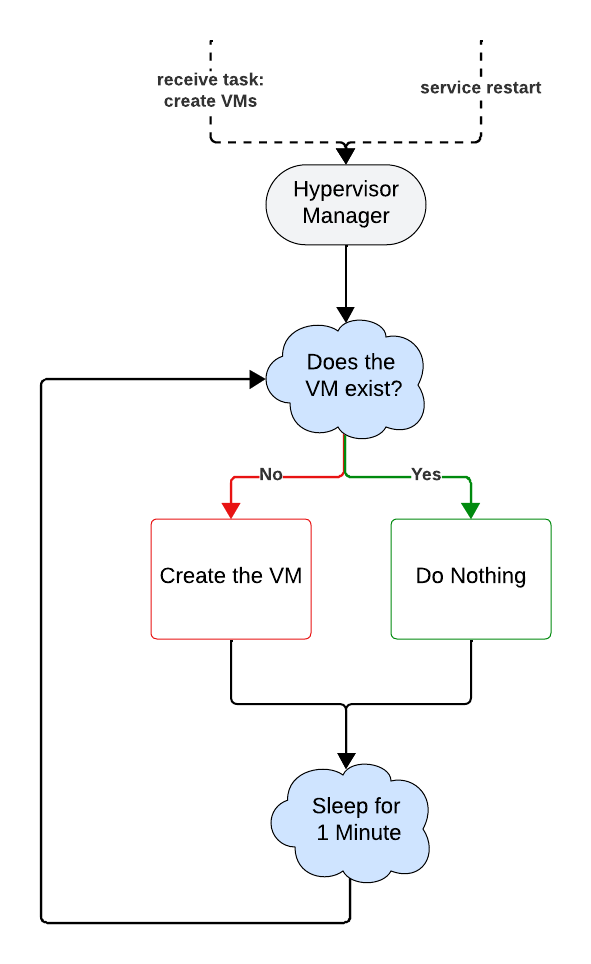
In this simple example, mariner is managing virtual machines. Instead of
requesting to create or destroy a specific VM, we ask for the existence or non-existence
of a VM. Mariner then, is responsible for observing the VM’s current state and what work
it needs to do so that the VM exists. Afterwards, it will periodically check if
it still exists, and if not, creates it again.
For MergeTB development, we call a specific unit of desired state (like the existence or non-existence of a VM) a task.
Pub/Sub
We send out the task as a message under the
Services subscribe for tasks they’re responsible for and reconcile towards it.
For MergeTB development, we call these services that are subscribers and work on these tasks a reconciler.
Once the reconciler has handled its task, it “replies” by sending its own status message,
which includes a fair amount of metadata (like the time the task was finished, whether it succeeded or not, and any messages for users and developers to look at).
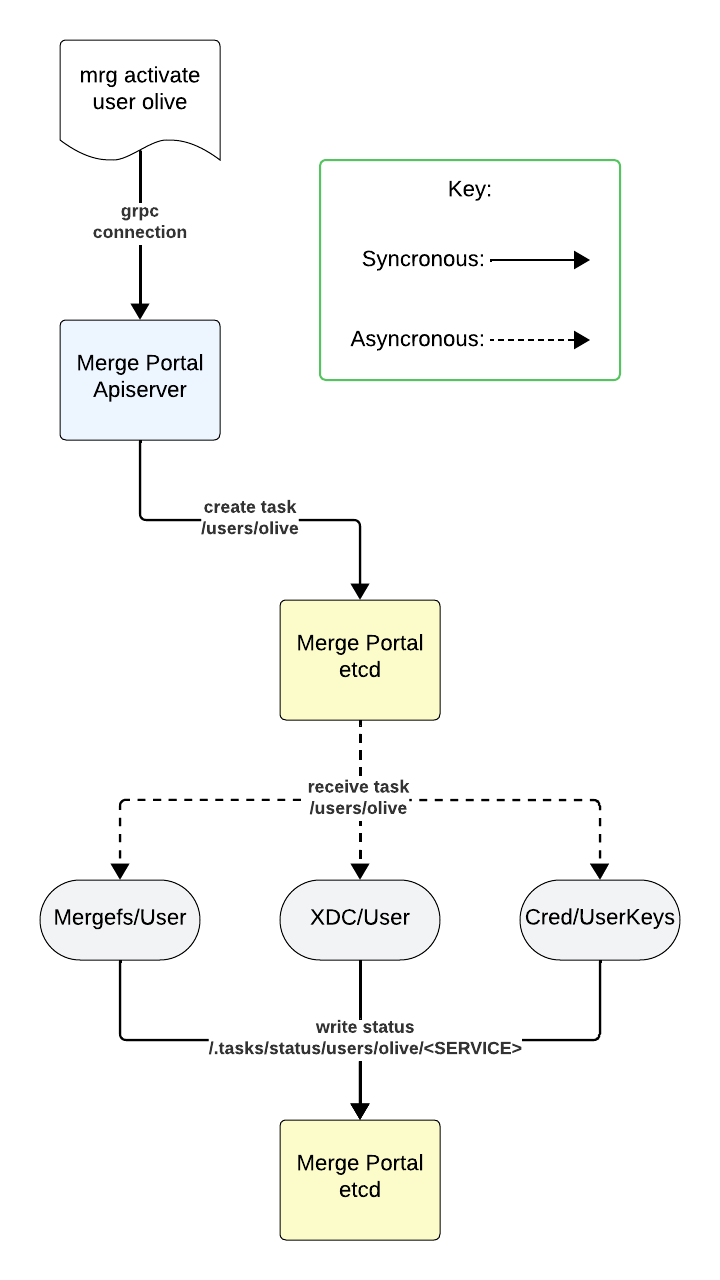
In this example, the user olive is activated /users/olive by a user, which is then picked up by serveral services, which then reply after handling the task.
Persistence
The reconciler-specific twist that MergeTB introduces
is that we want all of the current tasks and their corresponding status messages to be persistent.
A typical implementation of the Pub/Sub model (like Google’s Pub/Sub)
deletes messages after all subscribers have received the message once.
We always want reconcilers to drive towards the desired state,
even if the machine they’ve been on has been restarted and wiped,
or if something, for whatever reason, falls over later on.
As a result, we need to be able to check all of the current tasks of the system at any moment in time, hence the need for persistence.
In our implementation of the MergeTB Portal and Mars facility implementations,
we use etcd as the message bus and the data store of the tasks and statuses, hence its vital importance to us.
If etcd chokes, has issues, or disappears, the entire system will have issues.
MergeTB Data Flow Example
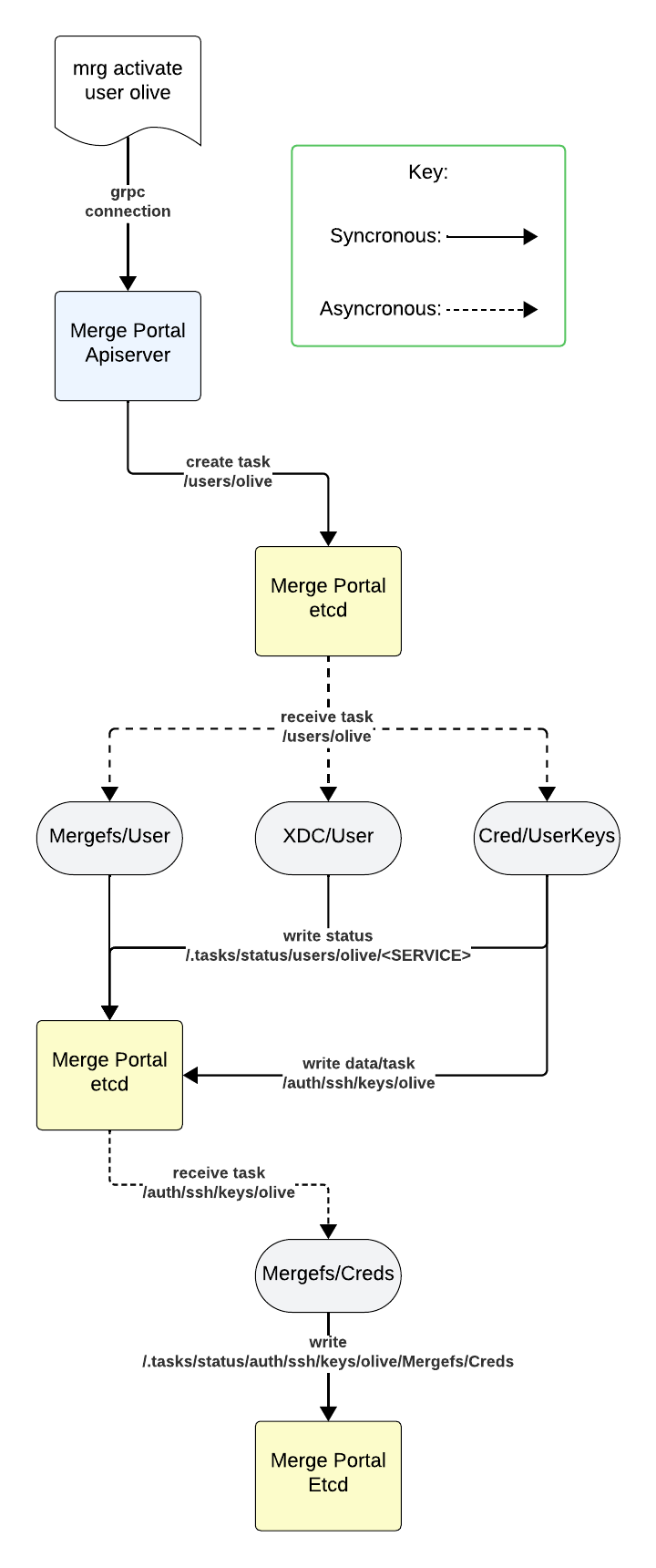
In this example:
-
A user runs the cli command,
mrg activate user olive, connecting to the apiserver. -
The apiserver writes the task
/users/oliveintoetcd. -
Each service receives the task
/users/olive:
-
Mergefs/User, which makes home directories for it onmergefs -
XDC/User, which adds the user to thessh-jumps -
Cred/UserKeys, which creates SSH keys for the user in/auth/ssh/keys/olive
-
Once each service handles the key, they each individually reply by writing into
/.tasks/status/users/olive/<SERVICE>. -
Mergefs/Credsnow receives the task/auth/ssh/keys/olive, which writes the SSH key intomergefs. -
Finally,
Mergefs/Credsreplies that it handled the task by writing into/.tasks/status/users/olive/Mergefs/Creds.
Dealing with Asynchrony
In MergeTB development, we call a collection of tasks that represent some emergent behavior a goal.
An example of this is a materialization, which relies on all of its subtasks to exist.
In order to manage asynchrony, the starting point is to read all of the replies to all tasks for the goal in question, whether if it is the user requesting status on that goal or the apiserver, wondering about a prerequisite goal. For example, XDC attachment can only work if the XDC is ready.
There are, however, a couple of things to keep in mind to accomplish this:
-
Tasks can have multiple replies.
-
Tasks can create other tasks.
-
The tasks required for a goal can change.
-
This mostly deals around wireguard attachment: an XDC works if and only if the wireguard attachment for it works.
Tasks Having Multiple Replies
By storing the reply at /.tasks/status/<TASK>/<SERVICE>, we can read all of the replies for a task by reading /.tasks/status/<TASK>/*.
TODO: For a given task, add the ability to specify which services reconcile upon that task, so when all of the following conditions apply:
-
a task is handled by multiple reconcilers
-
the task is new (aka, there is no old, outdated status for it)
-
one of its reconcilers is offline
Then the status for the missing replies can be set to “Pending” (which means that no work is currently being done on the task).
TODO: Figure out how to update when the reconcilers on a task change.
-
Under a dynamic system (like having the reconcilers register themselves), this is pretty easy.
-
Under a static system (like storing this in the code), we might have to store these into etcd at time of api call?
NOTE: On the facility, the running reconcilers are dependent on the facility model (for example, canopy/x0 is distinct from canopy/x1).
Tasks Creating Other Tasks
In the end, we need to account for every task.
If this is explicitly accounted for beforehand, then it’s not a problem, but then we have to maintain an explicit list of tasks for every API function.
-
An error in this case would if for whatever reason, the list given is inaccurate.
-
This can easily happen if how keys are written change between versions (like how VTEP handling on the facility has changed from
canopytomars-ifr).
Another solution is to write in the reply that the service wrote a task, so when we read that reply, we can grab the replies of the task that it wrote.
- An incomplete tree will be given if the parent reconciler of a task is offline during its execution.
Both of these should probably be done, as a sort of sanity check on each other during errors.
Required Tasks Changing
This implies that a completely static list of tasks will not work.
So, we have to maintain a dynamic list of tasks when this situation occurs, mostly for materialization and wireguard.
Dealing with Delete Asynchrony
TODO: The basic idea is that when we have delete into create,
create should be able to check if we have a delete in progress (by checking the goal for that), and if so, bail.
This is mostly relevant for re-materializations and XDC attachment.
NOTE: Goals differ between create and delete for materializations (and likely other objects),
so there will be separate goals for both create and delete.
The reason is that some tasks represent shared resources, like that a hypervisor is running and imaged,
which needs to be checked on create and remains present on delete.
We could use UUIDs, but that makes things a lot more complicated,
since we and users would have to store and track UUIDs.
I don’t like doing kubectl get pods; kubectl logs POD-UUID, and it’s kinda already a burden to do
mrg show mat REAL.EXP.PROJ.
(As a side note, I kinda wish we have autocomplete, so if REAL is unique, then mrg show mat REAL would work.)
Dealing with Multi-Site Goals
Goals have been implemented as being able to contain other goals.
So, each individual facility’s goals can be aggregated into a supergoal.