In the past we have seen issues with the speed of large experiment host configurations for the simple reason that each host takes an absolute minimum of 14 seconds to configure, even if there’s nothing to do. This is because a push host configuration architecture must negotiate an ssh connection, gather current configuration information, and finally run any configuration directives. Multiply this by 100 machines and you’re waiting a little while. Multiply by 500+ machines, and you’ve got a very long wait plus a bit of a mess on your hands if anything went wrong during either the materialization or the host configuration.
Most enterprise/commercial configuration as code solutions support a pull architecture that reduces the reliance of large deployments on the throughput of a single thread, system, or operator, and pushes the application of host configurations down to the compute cycles of each host.
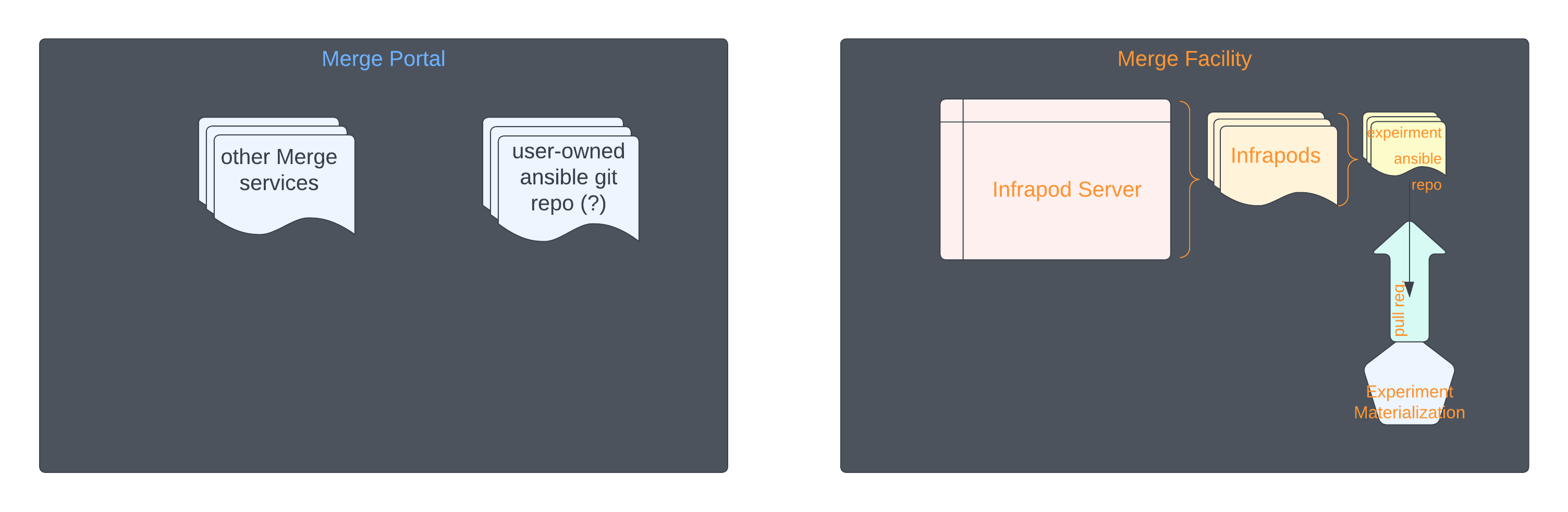
The current paradigm and our extended documentation regarding host configuration references ansible, which is a very common host configuration tool. To begin managing pull configurations, the host must known a few things…
- the schedule on which to run the command (using
atorcron) - the remote location of the repository of the ansible roles
- the remote location of the repository of the ansible playbooks to run
- the remote location of the ansible inventory to use when running the plays/roles
- the command to run, including any extra variables or configurations
I’ve created a bad diagram of sort of how I imagine this to happen. the design is up for discussion in this thread.