This post proposes support for storage devices and artifacts as first class entities in Merge
Conceptual Model
The image below illustrates the conceptual model
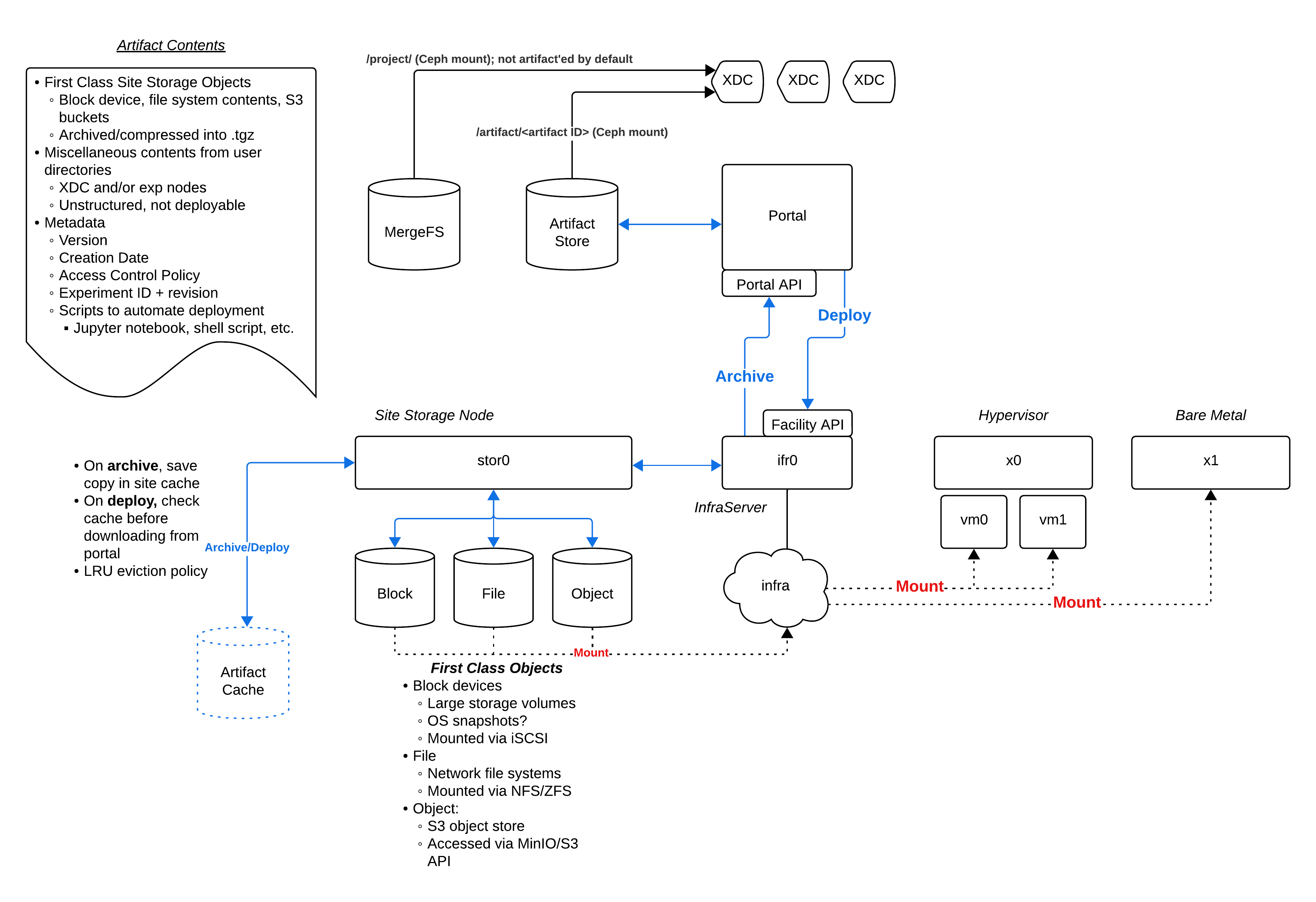
Let’s highlight the key components:
Dedicated storage resources
The site support a notion of first class mass storage devices. These include:
- Block devices: i.e., the type of device that typically presents at /dev/sd[a,b,c,...] in Linux (e.g., a hard drive). Users can partition them, format them with filesystems, etc., or simply leave them as raw storage devices. These are mounted via iSCSI and, at least initially, will only be available for virtual machines. Bare metal support is possible but may require BIOS/UEFI integration.
- Filesystems e.g., NFS or ZFS. These are network mounted somewhere like /nfs/... on the desired exp nodes. Available to bare-metal and VMs
- Objects e.g., S3 buckets. These are accessible via MinIO using the S3 storage API. Available to bare-metal and VMs
Network accessibility
All mass storage devices are accessible over the Merge infranet. Raw storage devices should likely be provisioned on a dedicated storage node or storage cluster (e.g., stor0 above), but could be hosted on infrastructure server to reduce cost and cabling needs (e.g., ifr0)
Artifacts
Artifact archival
While mass storage resources live on the site, artifacts are stored on the portal. Storage devices can be made into artifacts via the archival process (we can consider a different name). Archival is explicitly requested by a user through the Merge API. Archival involves packaging up storage device contents, creating a compressed tarball, and transferring to the Merge portal where it will be placed in a dedicated storage volume on the portal storage cluster.
Artifact contents
Artifacts consist of data and metadata
Artifact data includes:
- Zero or more site storage devices
- Zero or more directories uploaded from experiment nodes
- Zero or more directories uploaded from an XDC
Artifact metadata includes:
- Version number
- Creation date
- Access control policy (i.e., who is allowed to access?)
- Deployment metadata:
- Merge Experiment ID (e.g.,
botnet.discern) - Scripts to facilitate deployment/experiment provisioning
- e.g., Jupyter notebook
- Merge Experiment ID (e.g.,
Artifact deployment
First-class objects can be deployed automatically. When a user deploys an artifact, we check the artifact metadata for the experiment ID. The experiment XIR tells us which types of devices are present and which site they must live on. Merge then realizes+materializes a version of that experiment, and then the site provisions the storage resources. The site may have them cached locally in the artifact cache, but otherwise must download them from artifact store on the portal
Unstructured data can be created in artifacts. This includes arbitrary directories from experiments nodes or XDCs. We don’t deploy these given we don’t have enough information about where they came from in the first place (assuming they were simply uploaded via something like mrg create artifact --upload <path to directory>). Note, however, that a user could write a Jupyter notebook or script that would take this unstructured data and deploy it through any process they like.