Problem
Currently there is a separation of responsibility between the Merge portal and testbed facilities where the Portal computes an abstract embedding of an experiment into a network of resources - and it’s the facility’s responsibility to translate that abstract embedding to a concrete representation that defines how the networks that interconnect nodes within a materialization will actually be constructed. The ideal in play here is separation of responsibility. The portal does not need to know about the specifics of the technologies in play in a particular facility, and it’s up to the Cogs to figure out how to take an embedding specification and materialize it.
However, this separation results in a sort of false distinction. If we look at the code that implements realization and materialization in the portal, and then look at how link planning is done by the fabric library in the Cogs there is a lot of logical duplication between the two. Yes the realization engine provides hints like the number of lanes facilitated by any particular virtual network path and this information is used to cut down on the amount of logic, computation and complexity taken on by the Cogs fabric library, none the less the fabric library is doing a lot of the same things the realization engine is doing. This results in a weak complexity boundary, complexity duplication and a large opportunity for the introduction of bugs and performance degradation.
Solution
This RFC partitions complexity between the portal and testbed facilities with regard to network materialization along a different axis. The act of planning a network embedding, all the way down to the protocol specific specifications such as VXLAN/VLAN/EVPN is handled by the portal as a part of realization. The act of provisioning a virtual network plan remains the responsibility of the Cogs.
At first glance, this may seem to make Merge more monolithic, lose some of it’s principally designed distributed nature and degrade the experiment-space/resource-space boundary.
However, Merge has always been a model driven architecture, and the realization service has always used information in testbed resource models to determine an embedding. We are now simply taking the additional step of incorporating protocol information into realizations (such as VXLAN VTEP placement) that are determined using resource capability specifications from the model itself. So the propagation of information upwards has not changed with respect to the resource-space/experiment space boundary. What has changed is the addition of protocol information downwards. This information is not tied to particular resources, but to classes of resources that carry a capability specification sufficient to support a given protocol. Thus, we’re not getting into resource specifics in the portal, but we are providing materialization information based on resource classes.
Details
API Additions
The Realization API now includes network virtualization protocol objects as a part of Link realizations.
Link Realizations as Blueprints
With the addition of virtual network protocol data, link realizations now provide sufficient information to act as blueprints for experiment network materialization. These blueprints define what a link embedding is in terms of 3 core concepts.
Segmentation
Segmentation defines how an link is broken up into isolated virtual overlay segments. The primary reason for needing more than one segment for a given link is to accommodate network emulation. Consider the following diagram.

On the left, basic links are planned as single segments. For a VXLAN based network this means the same VNI, likewise for VLAN this means the same VID. The realization engine chooses what isolation protocol to use based on the capabilities of the network elements between the nodes chosen in the realization. This brings up a critical aspect of this approach, if the network encapsulation mechanism is indeed a part of the experiment specification (as in some cases it may be) then treating protocol level details at realization time is a fundamental requirement.
On the right, emulated links are planned as a segment per endpoint. This is required to make traffic flow through a network emulator. When the realization engine sees that a link is emulated, it will build a 1:1 segment/endpoint plan to the emulator that was chosen by the realization. Another benefit here is that we can effectively use emulator placement in concert with protocol path viability as a degree of freedom in embedding at realization time.
Termination
Link termination deals with what the endpoints are on a virtual link and what protocols are used to bring end-user testbed resources onto a virtual link. The following cases are considered
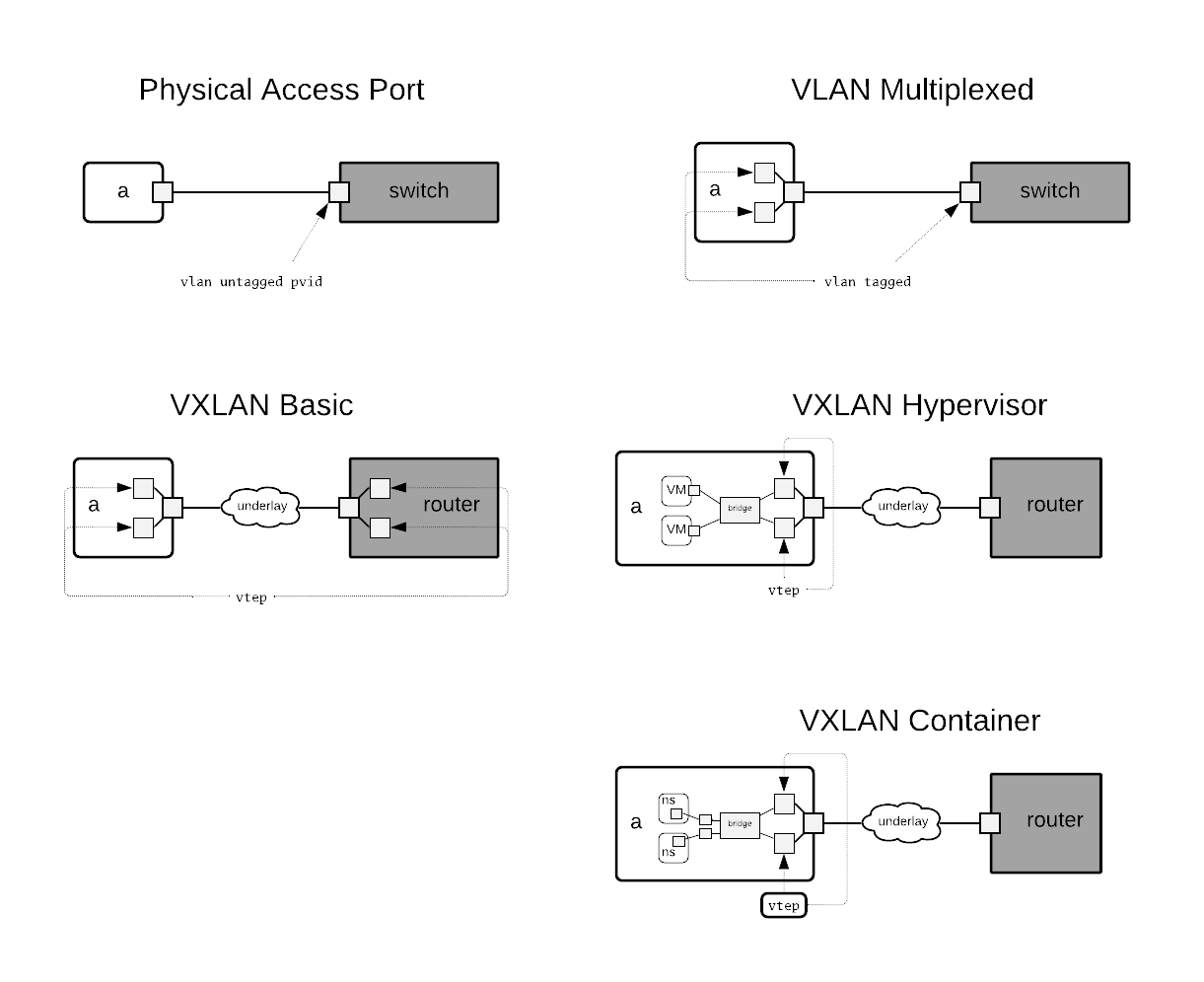
Physical Access Port
This sort of termination is used when
- The experiment requires use of the physical port on a testbed resource.
- The experiment requires use of the physical resource and the fan-out of the experiment node is <= than that of the physical resource.
- The physical resource does not support virtualization and the fan-out of the experiment node is <= than that of the physical resource.
VLAN Multiplexed
This sort of termination is used when
- The experiment requires use of the physical resource and the fan-out of the experiment node is > than that of the physical resource.
- The physical resource does not support virtualization and the fan-out of the experiment node is > than that of the physical resource.
VXLAN Hypervisor
This sort of termination is used when
- The node is realized as a virtual machine using a tap-backed virtual network interface
VXLAN Container
This sort of termination is used when
- The node is realized as a container using a veth-backed virtual network interface
- Currently the only nodes that use this sort of termination are CPS Sensors and Actuators
VXLAN Basic
This sort of termination is not currently used, but may come into play similar to VLAN Multiplexed in concert with VRF on an attached switch.
Transit
Link transit deals with how traffic flows between link terminals. 3 cases are consiered
VLAN Trunking
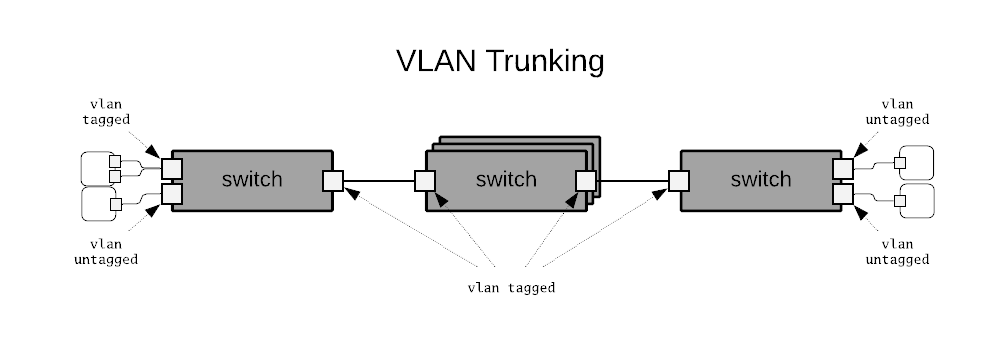
This case deals with a pure VLAN overlay. Physical access terminations are denoted as VLAN untagged and VLAN multiplexed terminations are denoted as VLAN tagged. In this transit scenario leaf switches connect to other leaf switches through intermediary switch connections on trunked VLAN ports. The intermediary switches may have an arbitrarily complex turnk interconnection topology that is shown as a stacked set of switches for simplicity in the diagram.
VXLAN Overlay
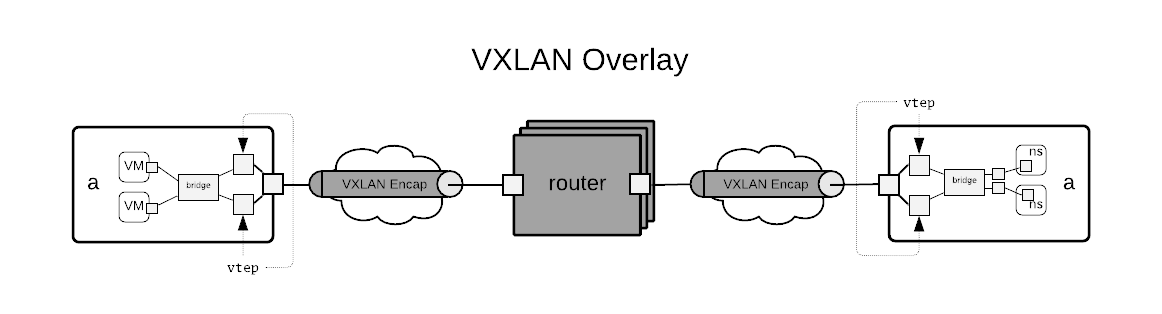
This case deals with a pure VXLAN overlay. The diagram shows two hypervisors connected to a network of routers. Each hypervisor has a set of VTEPs whose remote tunnel endpoint goes through it’s first hop router. The routers in the core of the network need not know or understand VXLAN as there is no encap/decap going on there. The routing network can be any routed network. In Merge we typically use a BGP underlay and route VXLAN over the top with EVPN.
Hybrid VLAN VXLAN
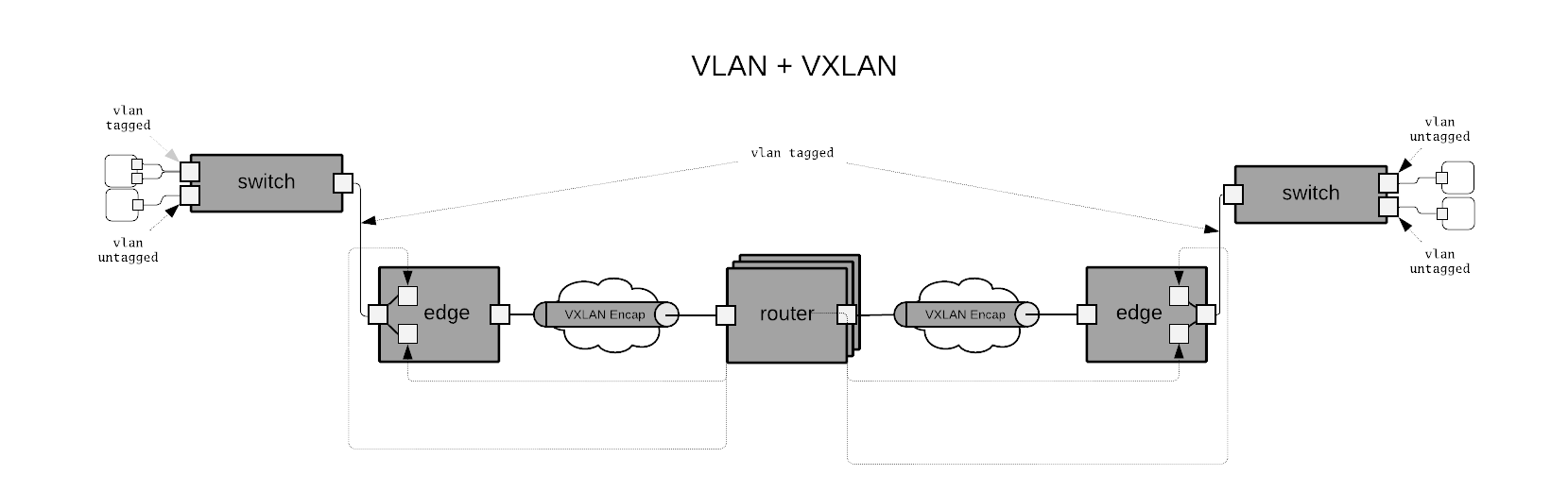
The hybrid case combines the previous two cases by supporting VLAN access networks at the edge of the overall network and interconnects everything through a routed VXLAN core. In the diagram a special edge device is shown that performs VXLAN encap/decap on behalf of the lower VLAN based network. This is a useful setup for supporting physical device provisioning where the first hop switch does not support VXLAN encap/decap in hardware (common situation in 1G switching platforms)
Summary
This RFC for moving network planning from the Cogs to the Portal
- Eliminates duplicated complexity between the realization engine and the Cogs fabric library.
- Takes a more structured approach to network planning by defining protocol objects in terms of resource capability classes and exposes those protocol objects as first class API elements.
- Defines a different complexity boundary between the portal and facilities that focuses on planning vs provisioning instead of abstract vs concrete embedding.
- Allows for network isolation protocol requirements to play a first class role in realizations and expose constraints to users allowing for greater control.