Virtual Network Plumbing
In this post I’ll lay out the VM connectivity cases I’m looking to cover in the initial implementation of virtualization support in Merge. One of the primary implementation details I’ll be focused on in this post is what parts of the network are provisioned and managed centrally by the Cogs testbed automation platform, and what parts of the network are managed individually by hypervisors. This distinction essentially boils down to what virtual network identifiers need to be global, and what virtual network identifiers can be determined locally by a single hypervisor without broader coordination. In the diagrams that follow this distinction will be denoted by a horizontal dotted line bisecting the network elements.
The mechanisms for attaching virtual machines to an experiment network in the initial MergeTB release of virtualization capabilities will be the following,
- virtio
- vfio
- PCI passthrough
and their combinations.
Virtio
Virtio is in many ways the simplest model to support from a testbed-level networking perspective. In the absence of experimental constraints that preclude the use of virtio, this is the default mechanism that will be used. It’s also the most flexible as it allows for an arbitrary number of interfaces to be created for a given VM or set of VMs.
I say that this is the simplest model from the testbed-level networking perspective, because we can place the VTEPs directly on the hypervisor itself. Thus the hypervisor becomes a BGP peer in the the layer-3 testbed underlay network and no special plumbing is required in the core of the testbed network. In the limit, if a testbed is composed of entirely hypervisors, the testbed switching mesh is pure underlay, with zero VLAN, VXLAN or explicit EVPN configuration.
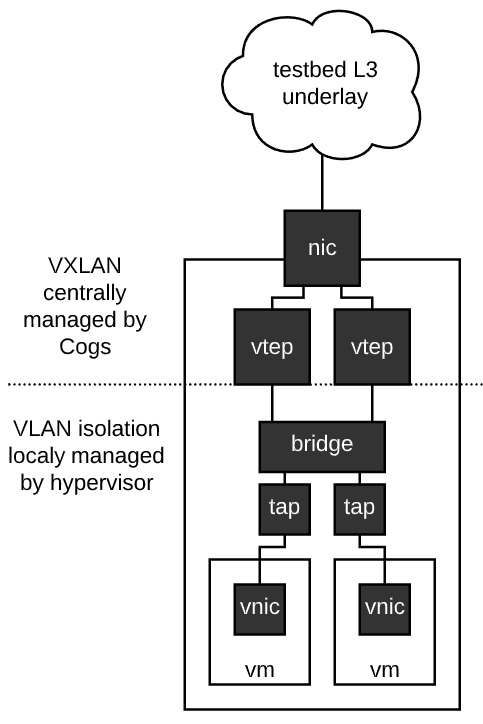
Global / Local Boundary
For the virtio mechanism, the cogs system will place VXLAN tunnel endpoints (VTEP) on the hypervisor before the virtual machines are set up. Then the cogs send a request to the hypervisor manager for virtual machines to be set up containing a mapping between the virtual NICs inside the virtual machine and the VTEP they are to be associated with.
It is the hypervisor manager’s responsibility to create the plumbing between the virtual NIC inside the VM and the associated VTEP on the machine that has been put in place by the cogs. In this example we have shown a strategy where the hypervisor sets up a bridge and a set of taps, and adds the provided VTEPs to the bridge. This bridge would necessarily be filtering bridge to prevent the VMs from talking directly over the bridge (this could be allowed in the case that it is explicitly desired, but is unlikely to be the general case for a network testbed, where the links between nodes are commonly emulated).
The nice thing about this design is it allows the machine level plumbing, which can have a significant impact on overall performance and introduction of artifacts, to evolve independently of the testbed level network plumbing. The stable point is that the touch point with the testbed at large will be a VTEP device.
Vfio
Vfio allows hardware virtualized segments of a NIC to be passed through to a virtual machine. In some cases this results an an increase in fidelity over the virtio device as the vfio device can be more representative of the feature set found on physical NICs, and the performance may be more desirable under certain conditions. None of these are hard and fast rules, it depends on the experimental situation at hand and what specific aspects of fidelity are important to maintain.
Vfio is a bit less flexible than virtio as there are limits on the number of devices that can be supported and it pushes the entry point into the testbed L3 underlay up to the connecting switch.
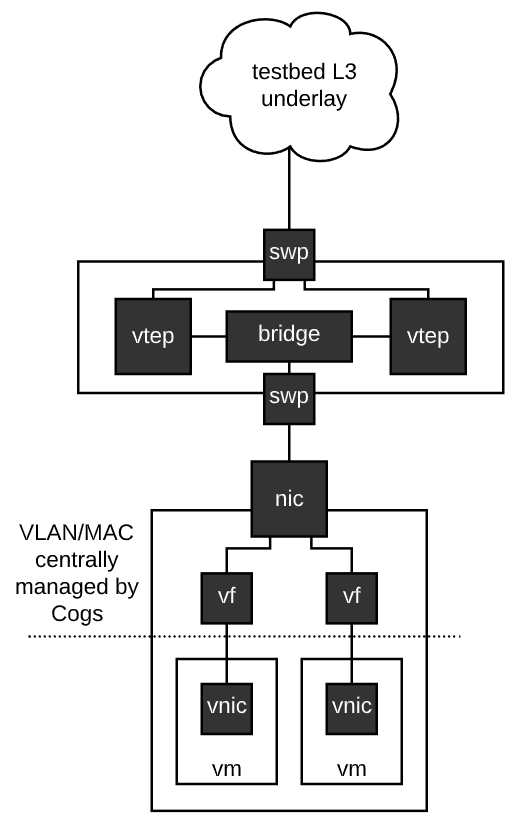
When a virtual function (VF) device is created based on a physical device that supports single-root input/output virtualization (SR-IOV), there are a few ways that we can isolate packets onto the appropriate testbed-level virtual network. I’m leaning toward the first option (VST) at this time.
VLAN switch tagging
VF devices on many Mellanox and Intel NICs allow for the VF to be transparently tagged with a VLAN ID. This is known as vlan switch tagging (VST). This makes the VF device act more or less like an access (untagged PVID) port on a switch. On egress from the VF the tag is applied so all outgoing traffic is tagged and may be handled appropriately upstream. On ingress, the VLAN tag is stripped so the virtual NIC inside the VM does not see these tags.
TODO: at this time it is not clear to me if VLAN stacking will work in this context e.g. if the experiment is using tagged VLAN packets itself, will the tags get stacked QinQ style, or will they be obliterated?
spoofcheck
Enabling spoofcheck on the VF device means that the guest inside the virtual machine cannot change the MAC address of the virtual NIC inside the VM, otherwise packets will be dropped. This allows us to strongly tie traffic coming from a specific VM interface to a particular logical interface as it pertains to the experiment’s network topology model. What this allows us to do, is set up the forwarding data base (FDB) on the bridge of the connected leaf switch to forward all traffic sourced from this MAC onto the desired VTEP which in effect puts the traffic in the correct global experiment level segment. The obvious disadvantage here is that changing the MAC is not available to the experimenter. This would almost certainly need to be done within the context of some sort of VLAN at the switch level to prevent MAC hijacking as well.
Global / Local Boundary
This discussion assumes that VST is the local isolation mechanism being used. In this case the VLAN tag selected must be viable for both the hypervisor and the leaf switch it’s connected to. For this reason, the VF devices and their configuration will be managed by the cogs. Prior to launching any virtual machines, the cogs will calculate the VLAN tags for all needed VFs, create the VF devices on the appropriate hypervisors and apply the VLAN tags. After the network setup phase, the cogs will send out virtual machines requests to the hypervisor managers that map VM virtual NICs to the appropriate VF devices.
Hybrid virtio + vfio
Virtio and vfio should be able to coexist. A point of interest is whether or not virtio and vfio can exist on the same NIC, and if they can is it a good idea to do so? If yes to both then the two may be freely intermixed up to the PF carnality limit for a given NIC. If no then once either mechanism is put to use on a particular NIC, the physical NIC is pinned to that mode of operation until the virtual NICs it is serving have been dematerialized.
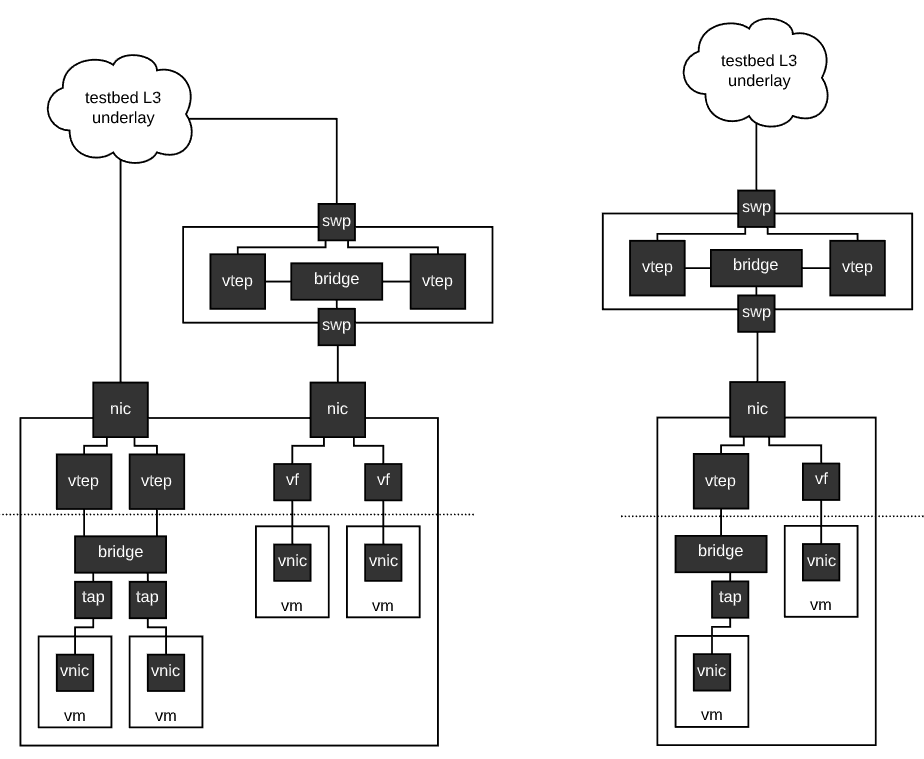
Global / Local Boundary
The hybrid state does not change the global / local boundary, it’s simply spread across two distinct mechanisms.
PCI Passthrough
In some cases use of an entire physical NIC with particular features is required. In this case PCI passthrough may be used.
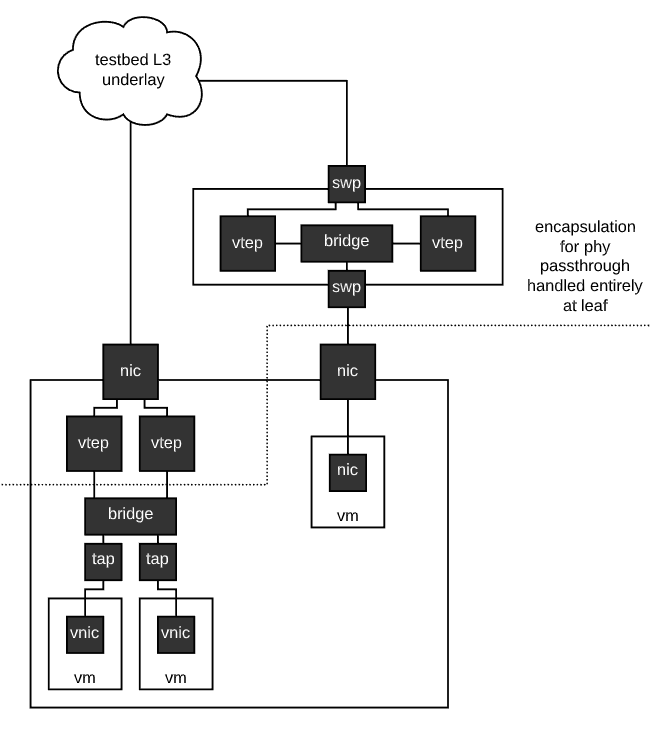
Similar to the VF case, encapsulation of traffic onto the appropriate testbed level virtual network is handled at the leaf switch. However, in this case it is not possible for the testbed to enforce a VLAN tag like we can for a VF. Thus the connecting switch port is operated in access mode - all ingress traffic to the switch port is tagged as it goes upstream to the experiment network at large, and all egress traffic is untagged as it goes downstream to the experiment node.
Virtual multiplexing of passthrough devices will not be supported. If testbed-based multiplexing of the device is required, virtio or vfio must be used. More generally, testbed automated multiplexing of virtual NICs within virtual machines through things like VLAN sub-interfaces that we currently provide for physical devices will not be supported - this is just the wrong way to do things. VLAN multiplexing for physical nodes is a necessary evil.