At a high level, Merge is a platform to describe networked system experiments, allocate sufficient resources to instantiate experiments, automate the materialization of an experiment, support the execution of experiments within a materialization and collect data.
At the time of writing, all Merge testbeds in production deal with physical nodes. This topic will describe the layers in the Merge stack that will need to be enhanced to support node emulation through virtualization. Support in some layers already exists as the Merge architecture and was designed to handle this capability from the outset.
Layers
Expression
There are many questions that arise at the intersection of experiment expression and virtualization.
- How are emulated node characteristics expressed by the experimenter?
- How does the experimenter influence the choice of virtualization techniques used to ultimately materialize nodes?
- How does the experimenter explicitly constrain experiments away from virtualization?
Much of this already exists. For example, in an experiment model the experimenter can say
x = topo.device('nodeX', cores == 4, memory == gb(8))
Here, the only underlying resource that will satisfy this experiment node is one with exactly 4 cores and 8 GB of memory. This may happen to exist in one of the resource pools the experimenter has access to, or it may not. In the case that it does not, a resource that supports virtualization may be used to create a satisfying virtual machine.
The experimenter should be able to explicitly opt-out of virtualization if they wish, or for that matter opt-in.
x = topo.device('nodeX', cores == 4, virt == true)
y = topo.device('nodeY', cores == 4, virt == false)
The experimenter should also be able to control specific parameters of interest as not all virtualization techniques are created equal. Take virtual network cards as an example. There are a wide variety out there that have different capabilities and performance profiles, virtio, e1000, vfio, passthrou, ve etc. In the following example the experimenter is specifying a requirement that one node uses a virtio virtual NIC and another uses a Mellanox ConnectX4 or newer physical NIC.
x = topo.device('x')
y = topo.device('y')
link = topo.connect([x,y])
link[x].spec(nic == virtio)
link[y].spec(nic >= connect4)
Compilation
In Merge the compilation phase accomplishes a few things
- Ensures the users model is syntactically correct
- Checks for some basic issues like islanded networks, malformed IP address specifications.
It’s not totally clear to me what ground the experiment compiler will need to cover specifically with respect to node emulation / virtualization. So this section is more of a place holder.
Realization
This is one place where some support for virtualization already exists. When the realization engine (Bonsai) runs. For each resource candidate it has to allocate to a node it first checks whether that resource has the VirtAlloc tag set. If it does the realization engine will allocate the experiment node as a slice of the resources owned by the resource, and an allocation is made in the allocation table. When subsequent realizations consider this node, the allocation table entries for this resource are fetched and the total available capacity of the resource is the difference between the base capability minus the current allocations against it. If the remaining capacity on the resource is not sufficient, the realization engine moves on.
The realization engine is generic in nature. It does not intrinsically understand the composition of resources or the specific elements within resources e.g. it has no idea what are core is or what a network card is. What it does understand is the experiment intermediate representation (XIR) schema, how that schema exposes properties in a semi-structured way and how to match experiment specifications to resource specifications. So the extent to which the realization engine is able to find what the experiment calls for, is the extent to which the underlying resource models contain sufficient information for doing so.
Materialization
Materialization is the process by which the resources allocated in the realization phase are turned into a ticking breathing experiment. In this phase all of the node and link specifications from an experiment are delivered to a testbed facility in the form of materialization fragments. These materialization fragments are generic containers of information that are self describing in terms of the type of information they carry and can be unpacked by testbed facility automation systems.
Automation
The prevailing testbed automation system that runs all current Merge testbed facilities is the Cogs. The cogs take these materialization fragments and turn them into a directed acyclic graph (DAG) of tasks that need to be done to perform the materialization. There is a pool of replicated workers (the worker is referred to as rex) that watch for new task DAGs in the Cogs data store and execute the graphs in an optimally concurrent way.
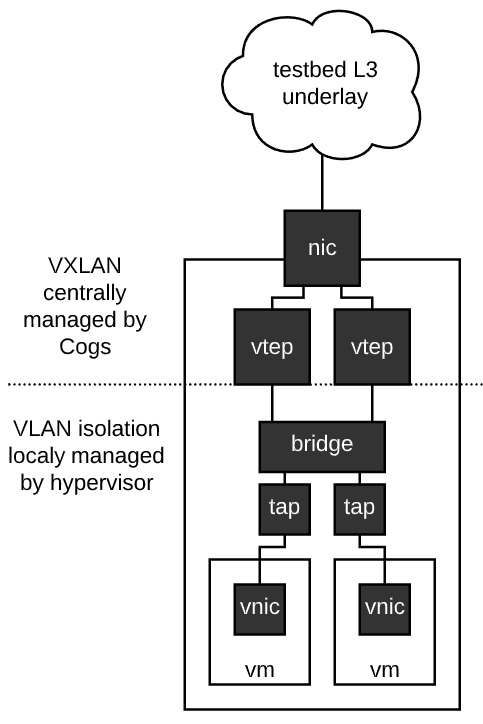
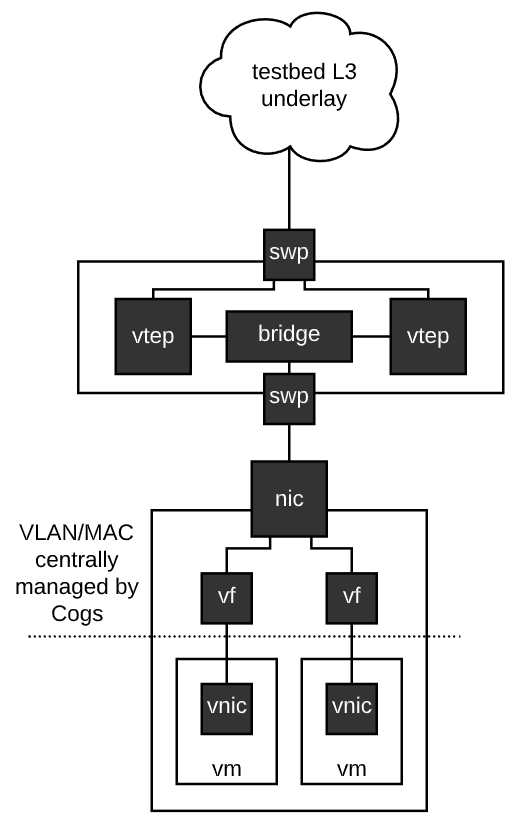
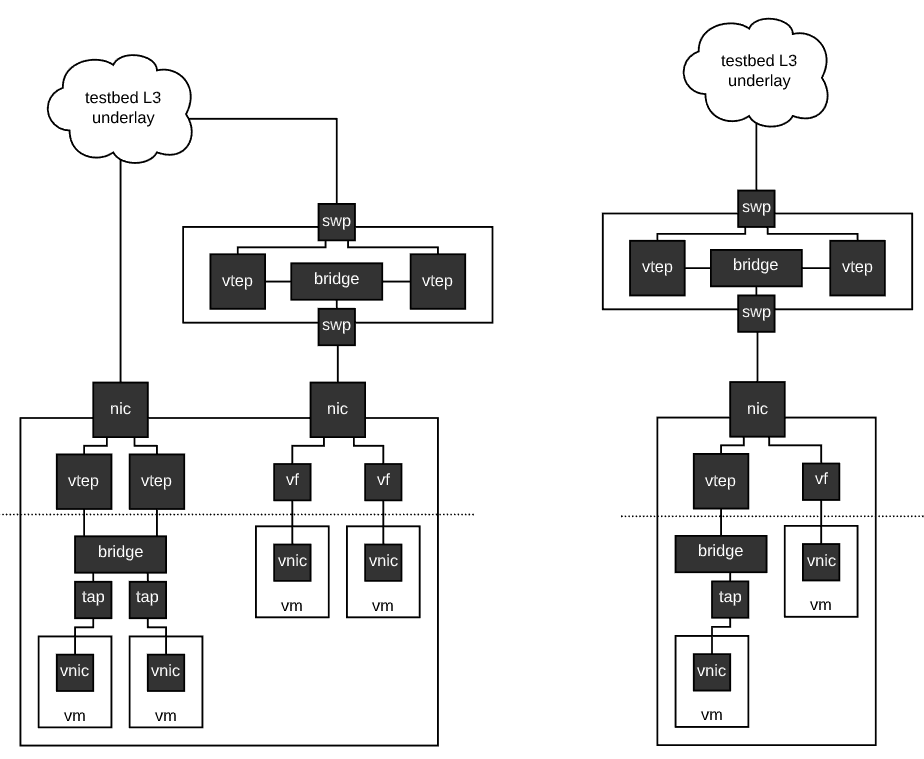
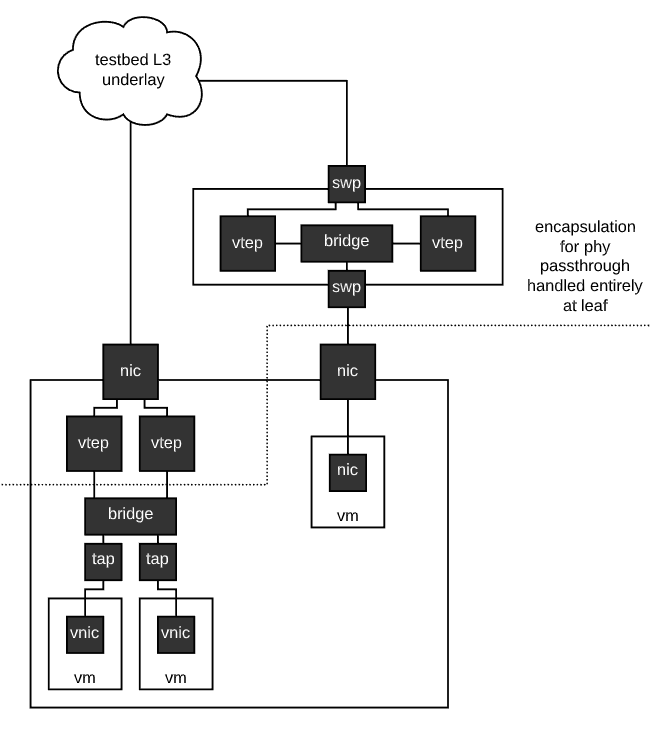
Rex does not intrinsically understand many of the tasks it does. For example, a common task is setting up DNS and DHCP for an experiment, or setting up VXLAN/EVPN domains for experiment links. Rex understands neither of these things. What Rex does understand is how to use the APIs of the various testbed subsystems that can do these things. This is a fundamental design of the Cogs automation system, the automation system itself focuses on fast and reliable automation and interacts with external systems through well defined APIs to implement specific capabilities. This is precisely how virtualization support will enter into Merge testbed facilities.
We have already begun work on utilizing the Sandia Minimega technology as a control plane for virtual machines. The idea here is that testbed nodes that support virtualization, that are currently in a virtual allocation state (some nodes support dual personality, and can be used as either a hypervisor host, or a bare metal machine) will run Minimega, and the Cogs will use the Minimega API to spawn, configure and generally control virtual machines.
Implementation
Underneath the covers of automating virtual machine provisioning through the cogs, is the fact that these virtual machines must be implemented in a way that honors the constraints laid out by the experiment specifications. This is similar in spirit to the network emulation systems we have - while the automation of network plumbing and general provisioning for network emulation is complex on it’s own - the implementation of correct network emulations is a field on it’s own. The node emulation facilities, implemented through virtualization have just as much complexity under the hood. One of the aims architecturally is to decouple automation and provisioning of node emulations from node emulator implementation.
The virtual machines in Merge will need to support advanced constraints and notions of fairness to be viable for rigorous experimentation. The biggest difference in the way testbeds use virtualization as opposed to most other platforms is that we want a virtual machine to run with a specific performance profile and not ‘as fast as possible up to some limit’. This includes but is not limited to.
- CPU bandwidth scheduling: ‘Give me a node with 4 cores at 2.2 ghz’
- Inter-component I/O: 'Give me a DDR 2400 memory bus and a PCIe 3.0 bus with 16 lanes).
- Network cards: ‘Give me a NIC with the following capabilities {…}’
- Time dilation: ‘Give me a VM that runs 10x slower than real time’
- Sender side emulation for virtual NICs: ‘Emulating wireless NICs, Emulating optical link dynamics’.
- Support for GPUs in pass-through and virtualized modes. The latter is quite interesting and is quite new so could be fun.
- Emulation on non x86 platforms. We can always use QEMU TSC for non-x86, but QEMU/KVM also works great on other platforms with full hardware virtualization support like ARM and to some extent RISC-V.