FastClick has been a constant source of pain on Lighthouse. Click threads die randomly; Buffers overflow leading to packet loss; general performance variability occurs when multiple Click instances are in the path of a flow. Initial experiments on ModDeter show the same behavior
This document outlines a possible new solution that removes the FastClick/userspace emulation component entirely, replacing it with a fully in-kernel solution that uses queuing disciplines and an eBPF program to shape traffic. This approach benefits from stable, kernel maintained queueing disciplines and eBPF infrastructure. It also removes polling threads from the Click approach, which while this will likely inject a small latency to each packet, is much more CPU efficient.
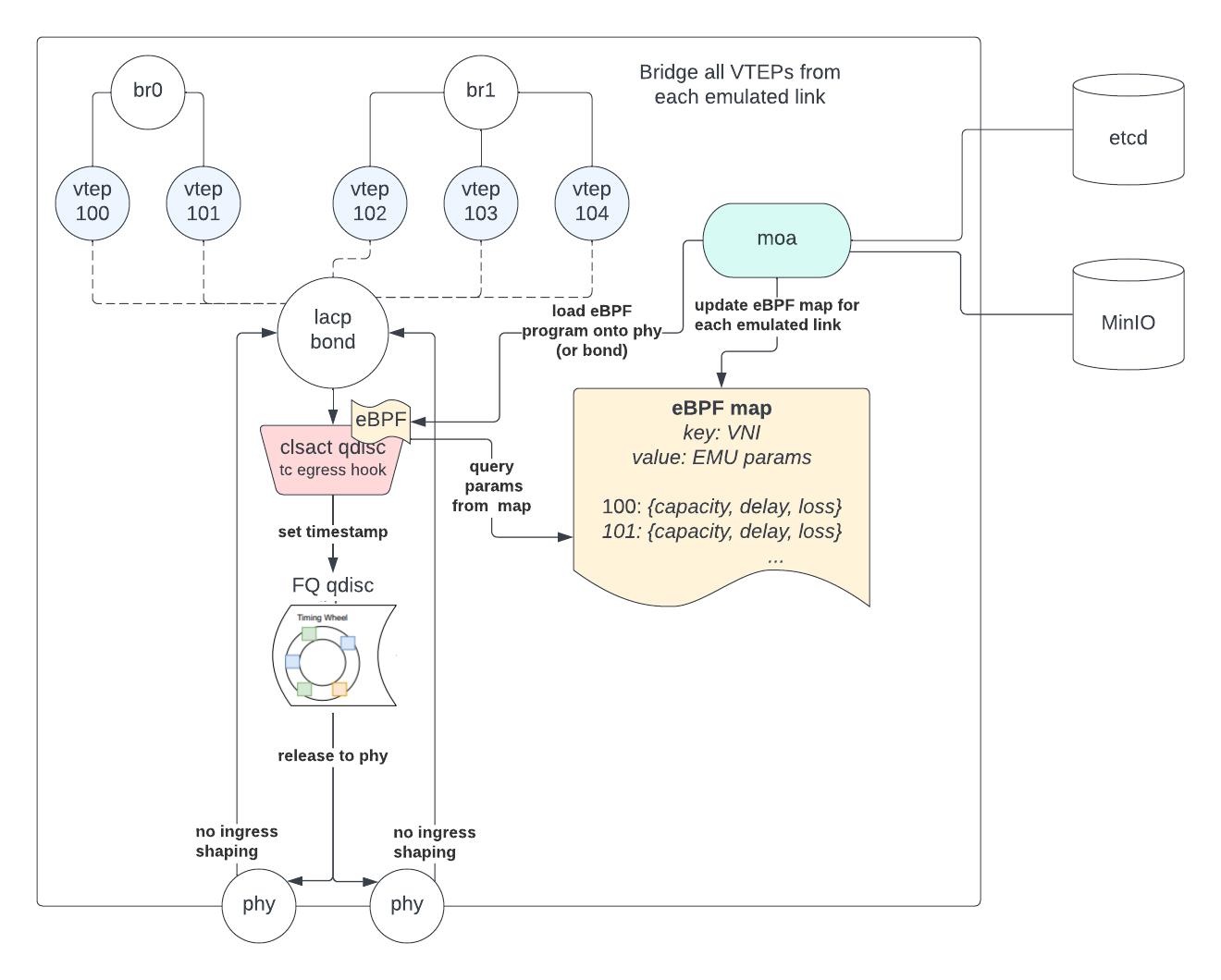
The architecture above describes the process. Let’s walk through the path of a packet through the Moa box:
VXLAN encapsulated packet for VNI 100 hits one of the phys
Packet is delivered through an lacp bond
Packet is delivered to vtep100 which decapsulates it
Packet hits br0, which forwards it to vtep101
Encapsulated packet with vni=101 is delivered back to the lacp bond
Finally something interesting happens. A clsact qdisc is attached on the egress path of the bond device. This classifier has a direct-attached eBPF program which:
Parses the pkt for headers (Eth, IP, UDP, VXLAN) and grabs the VNI
Indexes the eBPF map with key=101 and retrieves value={emu parameters for VNI 101}
Based on the values, either
Drops the packet (loss)
Delays the packet by modifying the packet timestamp (delay or capacity)
The packet with (possibly modified) timestamp is delivered to an FQ qdisc. The critical piece here is an in-kernel timer wheel that queues and orders packets based on their timestamps.
Once real time eclipses packet timestamps, packet is released to its destination (one of the phys)
I’ve successfully validated that an eBPF program can
Parse encapsulated packets off a physical device. I have not yet tested with bonds, but don’t anticipate any issues there
Modify packet timestamps
I’ve validated that end-to-end delay for pings in the user experiment network are modified as expected
The implementation is a work in progress, happening on my Mars dev branch
Disclosure: this approach is heavily based on a similar one described in
Noting also the P2P links (those with only 2 VTEPs) do not need to go all the way through a bridge. It would be possible to write an XDP program that runs directly on the VTEPs (not the bond) and xdp_redirects them to the other VTEP (i.e., vtep100 redirects to vtep101 and vice versa). This would be conceptually very similar to the v2v links in Raven , but does have the added complexity of needing to strip the outer Eth/IP/UDP/VXLAN headers before redirecting
Note that we would also need to have an ingress bandwidth shaper for LAN nodes, because the other nodes may be able to send more data that a receiver should receive (e.g. 3 nodes on a 1G LAN, with two nodes sending 1Gbps streams to the third node). In the current click model, we limit on both send and receive to prevent this problem.
I am curious to see how well this can scale up for topologies with a large number of links. Perhaps with your observeration that most point-to-point links don’t need the bridge device, that would help some.
I agree that performance with many links is an open question. I also wonder if even one or two high rate senders are going to cause problems for other links operating at lower rates. That all depends on how well the qdiscs are able to deliver packets on time.
Can you elaborate on the LAN issue? Assume a 3-node LAN {x0,x1,x2} with vteps 100,101,102. if x0 and x1 are both sending 1gbps to x2, there should be a 1gbps limit set when vni=102 packets hit the classifier, right? I could see how there would be a problem if the limits were imposed on 100/101, but not 102
Thanks for the clarification, I was thinking about it backwards. I see that my concern is handled because the 1Gbps limit will be set on the aggregate traffic sent to any node.
But now I think there is another concern. Consider a scenario where the three nodes in the LAN {x0,x1,x2} all have physical 10Gbps links, but the experiment topology specifies the LAN should have a 1Gbps limit. x0 sends 10Gbps of traffic to x2, while x1 sends 500Mbps to x2. In this case, there is the possibility that traffic from x0 will crowd out traffic from x1 because it will fill the egress tc buffers and cause packets to get dropped. In a real-world scenario, the excess 9Gbps of traffic would be dropped and not have this effect.